This is a simple tutorial showing how you can use R to extract information from a website. More specifically, we’ll be extracting linguistic data (Polish) from Wikipedia. You will need to have two packages installed: tidyverse and rvest. In addition, you need to have some familiarity with HTML, CSS, and regular expressions.
Understanding the structure of a page is essential in web scraping. You will always need to access the page source when you’re planning your task, since you must know where on the page a particular element is. If you’ve never done that, simply google “access page source in X”, where X is your browser. You will probably want to google how to “copy CSS or xpath from page”, because this will tell you the “address” of a particular object on a webpage.
Step 1: Our task
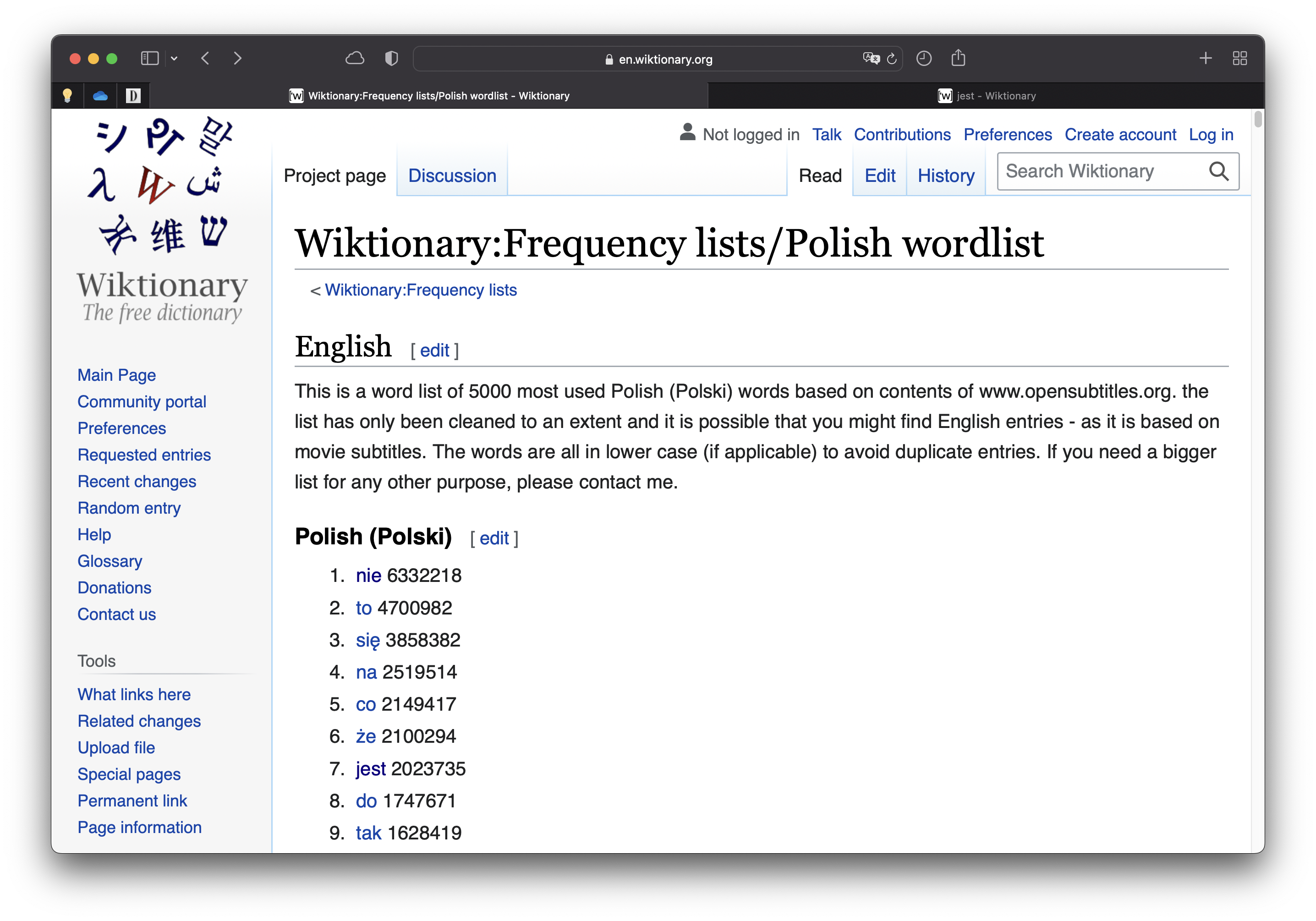
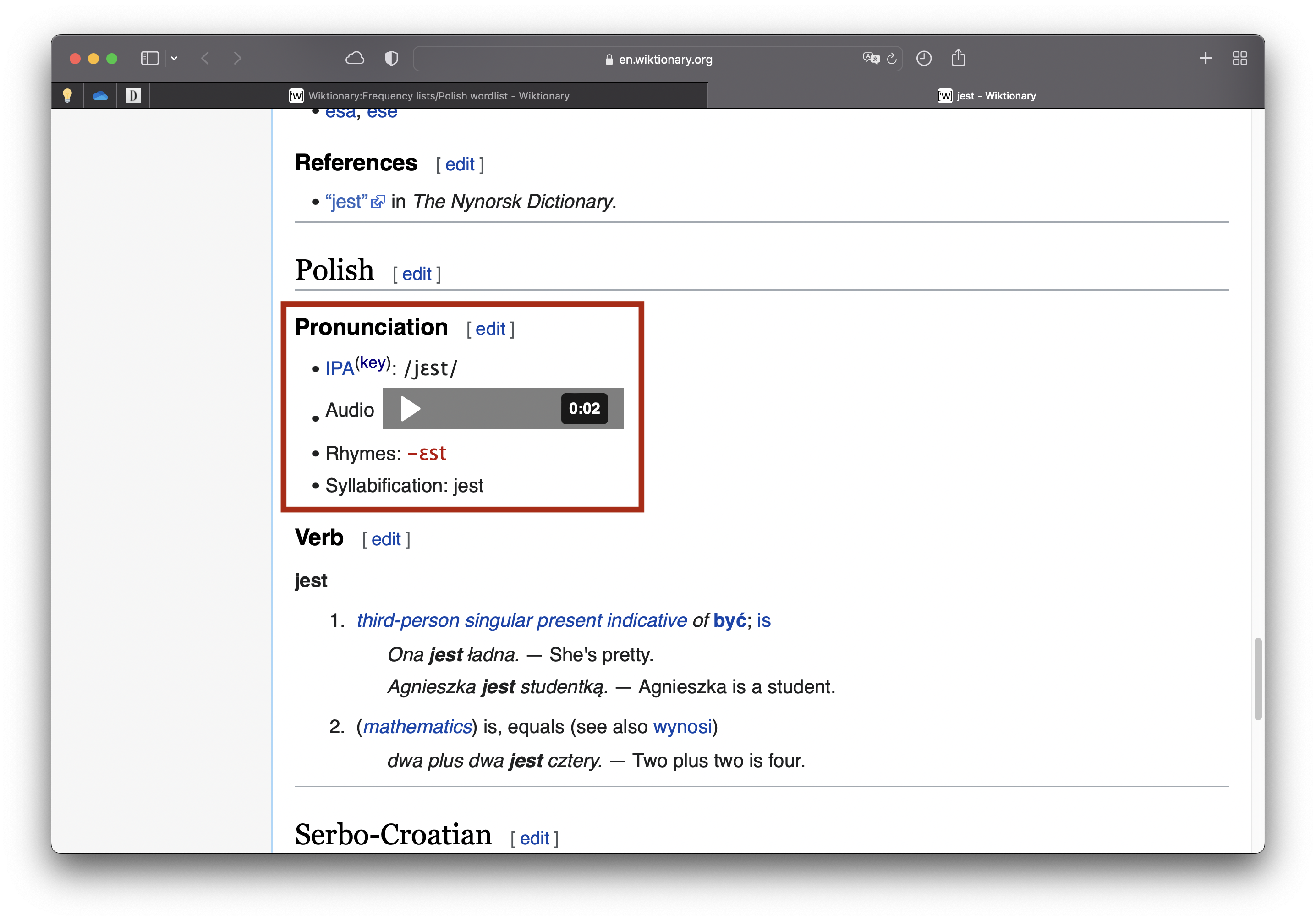
On this page, we have a list of 5000 Polish words (along with their frequency), which you can see in the figure on the left below (click to enlarge). If you click on any given word, you are taken to an entry (figure on the right) where, in most cases, you have access to the IPA transcription of the word.
Word list
Sample entry
Our task involves creating a table with three columns: Word, IPA, and Frequency. We can find the information for Word and Frequency on a single page (figure on the left above), but to extract the IPA for each word, we will need to “visit” every link for every word, find where the transcription is, and extract it.
Step 2: Words and frequencies
We start by loading our packages and importing our page of interest. The code below extracts the nodes we care about. We then use regular expressions to isolate the word and its frequency for one entry.
Code
library(rvest)library(tidyverse)# Main URL we will be usingmainURL="https://en.wiktionary.org/"# Read wordlistwikiURL="https://en.wiktionary.org/wiki/Wiktionary:Frequency_lists/Polish_wordlist"pol=read_html(wikiURL)# Create empty tibblepolish=tibble(Word =rep(NA, 5000), IPA =rep(NA, 5000), Freq =rep(NA, 5000))# Select frequenciess0=pol|>html_nodes("li")# Select only word entries# This contains both words and frequenciess0=s0[1:5000]|>as.character()# Select all words (no frequencies)s1=pol|>html_nodes("span")|>html_nodes("a")# Remove top rows (not words)s1=s1[4:5003]|>as.character()
Now we know how to do two thirds of our task for a single word. You should never start scaling up the task before you’re absolutely sure it works for a single element. Next, we need to get the pronunciation of a word. This is harder because it involves accessing an additional page.
Step 3: Transcriptions
The code below extracts the IPA transcription of the first word in our list. It already includes some bug fixes:
Not all words have a page for them. This will generate an error if not taken care of
Some words have a page but don’t have an IPA transcription, which will also be a problem for us
Both issues above are addressed in the code (NA is added). However, there is one problem the code doesn’t completely fix. The page for a given word is not exclusive for Polish. For example, if a word happens to exist in multiple languages (see figure on the right above), it will still only have a single page, with sections for each language. In other words, when you visit a page for any given word, it’s therefore possible to find multiple IPA transcriptions. How can we pick only the Polish one? This shouldn’t be a major issue, but the way the page was built makes it very hard to target only IPA transcription from Polish (given the hieararchical structure of the page).
The not-so-great solution in the code is actually very simple, and makes use of the alphabetical order in which language entries (and their transcriptions) appear on any page here: just pick the last IPA transcription you can find.
WarningWarning
The solution above will not always work. If, for example, a word exists in Polish and in Portuguese, we will be picking the one in Portuguese. This will be rare, though.
Code
ipa0=str_split(s1[1], " ")[[1]][2]ipa1=str_sub(ipa0, start =8, end =-2L)ipa2=str_c(mainURL, ipa1)# If page doesn't exist, skip to next word:if(str_detect(ipa2, "redlink")){next}ipa3=read_html(ipa2)ipa4=ipa3|>html_nodes(".IPA")|>as.character()# If node is empty (i.e., no IPA), skip to next word:if(is_empty(ipa4)){next}# Pick only IPAs with // or []:ipa4=ipa4[str_detect(ipa4, pattern =">\\[|\\/<")]if(is_empty(ipa4)){next}# Pick last IPA (see text above):ipa4=ipa4[length(ipa4)]ipa5=str_extract(ipa4, "(\\[|/)\\w*(\\.\\w*)*(\\]|/)")ipa6=str_replace_all(ipa5, "/|\\[|\\]", "")ipa6#> [1] "ˈɲɛ"
Step 4: Combining everything
The code below combines everything into a for-loop, so we can fill in the table we created above with all three variables of interest. The end of the code makes class adjustments and saves the final output as an RData file.
Code
rm(list=ls())library(rvest)library(tidyverse)mainURL="https://en.wiktionary.org/"pol=read_html("https://en.wiktionary.org/wiki/Wiktionary:Frequency_lists/Polish_wordlist")polish=tibble(Word =rep(NA, 5000), IPA =rep(NA, 5000), Freq =rep(NA, 5000))# Select frequenciess0=pol|>html_nodes("li")# Select only word entriess0=s0[1:5000]# Select all wordss1=pol|>html_nodes("span")|>html_nodes("a")s1# Remove top rows (not words)s1=s1[4:5003]# Loop to add words:for(iin1:nrow(polish)){# Pick wordword=str_extract(s1[i], ">\\w*<")|>str_remove_all(">|<")polish$Word[i]=word# Extract IPAipa0=str_split(s1[i], " ")[[1]][2]ipa1=str_sub(ipa0, start =8, end =-2L)ipa2=str_c(mainURL, ipa1)# If page doesn't exist, skip to next word:if(str_detect(ipa2, "redlink")){next}ipa3=read_html(ipa2)ipa4=ipa3|>html_nodes(".IPA")# If node is empty (i.e., no IPA), skip to next word:if(is_empty(ipa4)){next}# Pick only IPAs with // or []:ipa4=ipa4[str_detect(ipa4, pattern =">\\[|\\/<")]if(is_empty(ipa4)){next}# Pick last IPA:ipa4=ipa4[length(ipa4)]ipa5=str_extract(ipa4, "(\\[|/)\\w*(\\.\\w*)*(\\]|/)")ipa6=str_replace_all(ipa5, "/|\\[|\\]", "")polish$IPA[i]=ipa6# Extract frequenciespolish$Freq[i]=str_extract(s0[i], "\\s[:digit:]+")|>str_remove_all("\\s")}polishtail(polish)polish=polish|>mutate(across(where(is.character), as.factor))# Save RData:save(polish, file ="Polish.RData")
TipDownload
You can download the file here. Bear in mind that this may take 10–20 minutes to run, depending on your computer.
Below you can see a sample of 10 rows from our table.