pak::pak("guilhermegarcia/Fonology")La phonologie à partir du texte
la bibliothèque Fonology pour R
Fonology
corpus
maxent
SSHRC
CRSH
AstuceLe rôle des statistiques lexicales et post-lexicales dans l’acquisition d’une langue seconde
Comment identifier les patrons phonologiques d’une langue à partir de données écrites?
Nous voyons du texte partout, ce qui peut laisser croire que la collecte de données n’a jamais été aussi simple. Le problème réside dans le décalage bien connu entre les lettres (graphèmes) et les sons (phonèmes) : il est impossible de comprendre pleinement les systèmes phonologiques en se contentant d’examiner la distribution des lettres dans un corpus donné. Ainsi, pour identifier les patrons phonologiques, il faut d’abord convertir les graphèmes en phonèmes.
Cette série est consacrée à un projet financé par le CRSH (subvention no 141280) qui examine comment les statistiques lexicales peuvent être exploitées afin de générer une base de comparaison avec des données expérimentales. Une partie de ce projet implique le développement d’outils de conversion graphème-phonème (il est en effet très difficile d’analyser les patrons phonologiques dans des données écrites sans accès à une transcription phonétique). La bibliothèque R Fonology est directement liée à ce projet et couvre le portugais, le français, l’italien et l’espagnol. L’anglais (présenté ci-dessous) a été ajouté à la liste des langues prises en charge en 2026.
Fonology pour R
Fonology est une bibliothèque sur laquelle je travaille depuis 2023, à l’époque où elle ne prenait en charge que le portugais. En quelques mots, elle permet d’extraire des variables phonologiques à partir de données écrites. La bibliothèque prend maintenant en charge l’anglais (depuis 2026), le français, l’italien, le portugais et l’espagnol, avec différents niveaux de précision pour la conversion graphème-phonème.1 La démonstration ci-dessous est fondée sur un séminaire que j’ai donné à l’Universidad de Granada en avril 2026 dans le cadre du programme Erasmus+ (partenariat entre l’Université Laval et l’Universidad Granada). L’objectif est simple : prendre des données écrites, extraire des variables phonologiques et lancer un modèle MaxEnt pour apprendre des poids. Cela illustre comment Fonology peut être utilisé pour a) transcrire des textes dans plusieurs langues, b) extraire un large éventail de variables et c) lancer des grammaires probabilistes. Vous pouvez accéder à la bibliothèque ici, où vous pourrez en apprendre davantage sur toutes les fonctions disponibles. La courte démonstration ci-dessous ne représente qu’un sous-ensemble de ce que la bibliothèque peut faire, mais c’est probablement la façon la plus rapide de comprendre pourquoi elle existe.


Démonstration
Passons en revue une série d’étapes qui montrent comment Fonology peut être utilisé avec deux textes, l’un en anglais (Moby Dick) et l’autre en portugais (Memórias Póstumas de Brás Cubas). Pour illustrer différentes fonctions de la bibliothèque, nous suivrons les étapes suivantes :
- Transcrire phonémiquement les deux textes
- Extraire les structures syllabiques
- Lancer une grammaire MaxEnt pour les deux langues (Goldwater et Johnson 2003; Hayes et Wilson 2008)
- Tracer les poids des contraintes par langue
Étape 0 : Installer les bibliothèques
Nous utiliserons tidyverse, gutenbergr, tidytext et Fonology ci-dessous. Assurez-vous d’avoir installé toutes ces bibliothèques. Pour installer Fonology, vous pouvez utiliser pak (mais vous devrez d’abord installer pak).
Une fois toutes ces bibliothèques installées, vous serez prêt à passer à l’étape 1 ci-dessous.
Étape 1 : Charger les textes
Vous pouvez utiliser gutenbergr pour télécharger les deux romans du projet Gutenberg. Cette étape enregistre également les deux textes dans un seul fichier RData.
library(gutenbergr)
library(Fonology)
library(tidyverse)
library(tidytext)
# Télécharger Moby Dick
1gutenberg_metadata |>
filter(author == "Melville, Herman") |>
select(gutenberg_id, title) |>
print(n = 20)
2moby_raw <- gutenberg_download(2701) |> select(text)
# Télécharger Brás Cubas
gutenberg_metadata |>
filter(author == "Machado de Assis") |>
select(gutenberg_id, title) |>
print(n = 20)
braz_raw <- gutenberg_download(54829) |> select(text)
3save(moby_raw, braz_raw, file = "texts.RData")- 1
- Ceci nous permet d’afficher certains livres de Melville (et leurs identifiants) pour nous assurer que le texte visé existe
- 2
- Nous pouvons ensuite télécharger Moby Dick en utilisant son identifiant
- 3
-
Enfin, nous enregistrons le tout dans un fichier
RData
Étape 2 : Tokeniser et coder
Maintenant que nous avons enregistré nos textes, nous n’aurons pas besoin de télécharger les données de nouveau la prochaine fois. Le code ci-dessous suppose une session différente afin de montrer comment charger le fichier RData en question. Pour montrer comment les constituants syllabiques peuvent être extraits, le code ci-dessous récupère aussi l’attaque de la syllabe finale.
load("texts.RData")
md <- moby_raw |>
unnest_tokens(word, text) |>
filter(
1 !word %in% stopwords_en
) |>
2 mutate(
ipa = ipa(word, lg = "en"),
cv = cv(ipa),
weight = getWeight(ipa, lg = "en"),
stress = getStress(ipa),
finSyl = getSyl(ipa, 1),
onsetFin = syllable(finSyl, const = "onset", glides_as_onsets = TRUE)
)
bc <- braz_raw |>
unnest_tokens(word, text) |>
filter(
!word %in% stopwords_pt
) |>
mutate(
ipa = ipa(word, lg = "pt"),
cv = cv(ipa),
weight = getWeight(ipa, lg = "pt"),
stress = getStress(ipa),
finSyl = getSyl(ipa, 1),
onsetFin = syllable(finSyl, const = "onset", glides_as_onsets = TRUE)
)- 1
-
Retirer les mots vides du texte (la même chose est faite pour le texte portugais). Il s’agit d’une liste de mots incluse dans
Fonologypour toutes les langues prises en charge; ces listes proviennent de la bibliothèquestopwords - 2
-
C’est ici que se fait la plus grande partie du travail. Nous ajoutons plusieurs colonnes qui codent différentes variables phonologiques : la transcription, la structure CV, le poids, l’accent, la syllabe finale et l’attaque de cette syllabe. Ce sont toutes des fonctions de
Fonology
Ci-dessous, vous pouvez voir les tibbles obtenus. Pour l’anglais, la fonction ipa() utilise d’abord le dictionnaire CMU comme lexique de référence. Ensuite, elle consulte une deuxième base de données pour certains mots précis (un lexique personnalisé). Enfin, les mots qui n’existent dans aucune des deux bases de données sont transcrits à l’aide d’une série de règles. Comme la conversion graphème-phonème en anglais n’est pas très fiable, tous les mots dont la transcription API est dérivée par règles se terminent par un astérisque, ce qui permet de les vérifier ou de les retirer facilement. Pour Moby Dick, seulement 2 % des occurrences appartiennent à cette catégorie. Pour les autres langues prises en charge dans Fonology, la transcription est fondée sur des règles. Les lignes qui ne contiennent que des nombres sont codées comme NA (par exemple, les numéros de chapitre).
md # Moby Dick# A tibble: 81,958 × 7
word ipa cv weight stress finSyl onsetFin
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 moby ˈmoʊ.bi CVV.CV HL penult bi b
2 dick ˈdɪk CVC H final dɪk d
3 whale ˈweɪl GVVC H final weɪl w
4 herman ˈhɝ.mən CV.CVC LH penult mən m
5 melville ˈmɛl.vɪl CVC.CVC HH penult vɪl v
6 contents ˈkɑn.tɛnts CVC.CVCCC HH penult tɛnts t
7 etymology ɛ.tə.ˈmɑ.lə.dʒi V.CV.CV.CV.CCV LLL antepenult dʒi dʒ
8 extracts ˈɛks.tɹækts VCC.CCVCCC HH penult tɹækts tɹ
9 supplied sə.ˈplaɪd CV.CCVVC LH final plaɪd pl
10 librarian laɪ.ˈbɹɛ.ɹi.ən CVV.CCV.CV.VC LLH antepenult ən <NA>
# ℹ 81,948 more rowsbc # Brás Cubas# A tibble: 29,239 × 7
word ipa cv weight stress finSyl onsetFin
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 memórias me.ˈmɔ.ri.as CV.CV.CV.VC LLH antepenult as <NA>
2 pósthumas ˈpɔs.tu.mas CVC.CV.CVC HLH antepenult mas m
3 braz ˈbras CCVC H final bras br
4 cubas ˈku.bas CV.CVC LH penult bas b
5 machado ma.ˈʃa.do CV.CV.CV LLL penult do d
6 assis a.ˈsis V.CVC LH final sis s
7 rio ˈxi.o CV.V LL penult o <NA>
8 janeiro ʒa.ˈnej.ro CV.CVG.CV LHL penult ro r
9 typographia ti.po.gra.ˈpi.a CV.CV.CCV.CV.V LLL penult a <NA>
10 nacional na.si.o.ˈnal CV.CV.V.CVC LLH final nal n
# ℹ 29,229 more rowsÉtape 3 : Phonotactique
Ensuite, nous divisons les mots en syllabes, puisque la position de chaque structure CV n’est pas pertinente pour cette démonstration. On obtient ainsi une colonne cv modifiée où chaque ligne ne contient qu’une syllabe. Par conséquent, nos tibbles seront maintenant plus longs — voir les sorties ci-dessous. Nous pourrons alors calculer quelles structures syllabiques sont les plus fréquentes dans les deux langues en utilisant ces textes comme références.
md_phon <- md |>
separate_rows(cv, sep = "\\.")
# # A tibble: 151,453 × 7
# word ipa cv weight stress finSyl onsetFin
# <chr> <chr> <chr> <chr> <chr> <chr> <chr>
# 1 moby ˈmoʊ.bi CVV HL penult bi b
# 2 moby ˈmoʊ.bi CV HL penult bi b
# 3 dick ˈdɪk CVC H final dɪk d
# 4 whale ˈweɪl GVVC H final weɪl w
# 5 herman ˈhɝ.mən CV LH penult mən m
# 6 herman ˈhɝ.mən CVC LH penult mən m
bc_phon <- bc |>
separate_rows(cv, sep = "\\.")
# # A tibble: 80,910 × 7
# word ipa cv weight stress finSyl onsetFin
# <chr> <chr> <chr> <chr> <chr> <chr> <chr>
# 1 memórias me.ˈmɔ.ri.as CV LLH antepenult as <NA>
# 2 memórias me.ˈmɔ.ri.as CV LLH antepenult as <NA>
# 3 memórias me.ˈmɔ.ri.as CV LLH antepenult as <NA>
# 4 memórias me.ˈmɔ.ri.as VC LLH antepenult as <NA>
# 5 pósthumas ˈpɔs.tu.mas CVC HLH antepenult mas m
# 6 pósthumas ˈpɔs.tu.mas CV HLH antepenult mas mPour simplifier la comparaison entre l’anglais et le portugais, concentrons-nous sur les structures syllabiques les plus représentatives. Le code ci-dessous filtre les données et calcule les proportions dont nous aurons besoin plus tard pour notre analyse MaxEnt.
# MOBY DICK :
md_phon |>
distinct() |>
filter(cv %in% c("CCV", "CV", "V", "VC", "CVC", "VCC", "CVCC", "CCVCC")) |>
summarize(
obs = n(), .by = cv
) |>
mutate(
prop = obs / sum(obs)
)
# # A tibble: 8 × 3
# cv obs prop
# <chr> <int> <dbl>
# 1 CV 7345 0.301
# 2 CVC 7738 0.317
# 3 V 1633 0.0670
# 4 CCV 1843 0.0756
# 5 VCC 460 0.0189
# 6 VC 2217 0.0910
# 7 CVCC 2556 0.105
# 8 CCVCC 580 0.0238
# BRÁS CUBAS :
bc_phon |>
distinct() |>
filter(cv %in% c("CCV", "CV", "V", "VC", "CVC", "VCC", "CVCC", "CCVCC")) |>
summarize(
obs = n(), .by = cv
) |>
mutate(
prop = obs / sum(obs)
)
# # A tibble: 8 × 3
# cv obs prop
# <chr> <int> <dbl>
# 1 CV 8285 0.444
# 2 VC 1639 0.0878
# 3 CVC 5073 0.272
# 4 V 2142 0.115
# 5 CCV 1382 0.0740
# 6 CVCC 89 0.00477
# 7 VCC 28 0.00150
# 8 CCVCC 37 0.00198Étape 4 : MaxEnt
Enfin, à partir des résumés créés ci-dessus, nous pouvons maintenant générer nos tableaux avec la fonction tribble(). Nous avons besoin de colonnes pour l’input, l’output, les contraintes et le nombre d’outputs observés. Pour garder l’illustration simple, supposons les contraintes suivantes : onset, no_coda, no_complex_onset.
tableau_md <- tribble(
~input, ~output, ~onset, ~no_coda, ~no_complex_onset, ~obs,
"input", "CV", 0, 0, 0, 7345,
"input", "CVC", 0, 1, 0, 7738,
"input", "V", 1, 0, 0, 1633,
"input", "CCV", 0, 0, 1, 1843,
"input", "VCC", 1, 2, 0, 460,
"input", "VC", 1, 1, 0, 2217,
"input", "CVCC", 0, 2, 0, 2556,
"input", "CCVCC", 0, 2, 1, 580,
)
tableau_bc <- tribble(
~input, ~output, ~onset, ~no_coda, ~no_complex_onset, ~obs,
"input", "CV", 0, 0, 0, 8285,
"input", "VC", 1, 1, 0, 1639,
"input", "CVC", 0, 1, 0, 5073,
"input", "V", 1, 0, 0, 2142,
"input", "CCV", 0, 0, 1, 1382,
"input", "CVCC", 0, 2, 0, 89,
"input", "VCC", 1, 2, 0, 28,
"input", "CCVCC", 0, 2, 1, 37,
)Une fois le nombre d’observations copié à partir des résumés ci-dessus, nous sommes prêts à utiliser la fonction maxent(). Par défaut, la fonction retourne plusieurs éléments, mais les deux plus importants sont predictions et weights. Comme la sortie est une liste, vous pouvez accéder à ces éléments avec $.
maxent(tableau_md)$predictions
# A tibble: 8 × 13
input output onset no_coda no_complex_onset obs harmony max_h exp_h Z
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 input CV 0 0 0 7345 0 2.49 12.0 34.3
2 input CVC 0 1 0 7738 0.439 2.49 7.76 34.3
3 input V 1 0 0 1633 1.41 2.49 2.94 34.3
4 input CCV 0 0 1 1843 1.61 2.49 2.41 34.3
5 input VCC 1 2 0 460 2.29 2.49 1.22 34.3
6 input VC 1 1 0 2217 1.85 2.49 1.90 34.3
7 input CVCC 0 2 0 2556 0.878 2.49 5.00 34.3
8 input CCVCC 0 2 1 580 2.49 2.49 1 34.3
# ℹ 3 more variables: obs_prob <dbl>, pred_prob <dbl>, error <dbl>
$weights
onset no_coda no_complex_onset
1.4090772 0.4389564 1.6100479
$log_likelihood
[1] -42998.96
$log_likelihood_norm
[1] -5374.87
$bic
[1] -85991.67maxent(tableau_bc)$predictions
# A tibble: 8 × 13
input output onset no_coda no_complex_onset obs harmony max_h exp_h Z
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 input CV 0 0 0 8285 0 4.15 63.7 128.
2 input VC 1 1 0 1639 2.35 4.15 6.10 128.
3 input CVC 0 1 0 5073 1.09 4.15 21.5 128.
4 input V 1 0 0 2142 1.26 4.15 18.0 128.
5 input CCV 0 0 1 1382 1.98 4.15 8.76 128.
6 input CVCC 0 2 0 89 2.17 4.15 7.27 128.
7 input VCC 1 2 0 28 3.43 4.15 2.06 128.
8 input CCVCC 0 2 1 37 4.15 4.15 1 128.
# ℹ 3 more variables: obs_prob <dbl>, pred_prob <dbl>, error <dbl>
$weights
onset no_coda no_complex_onset
1.261392 1.085006 1.983917
$log_likelihood
[1] -28335.66
$log_likelihood_norm
[1] -3541.957
$bic
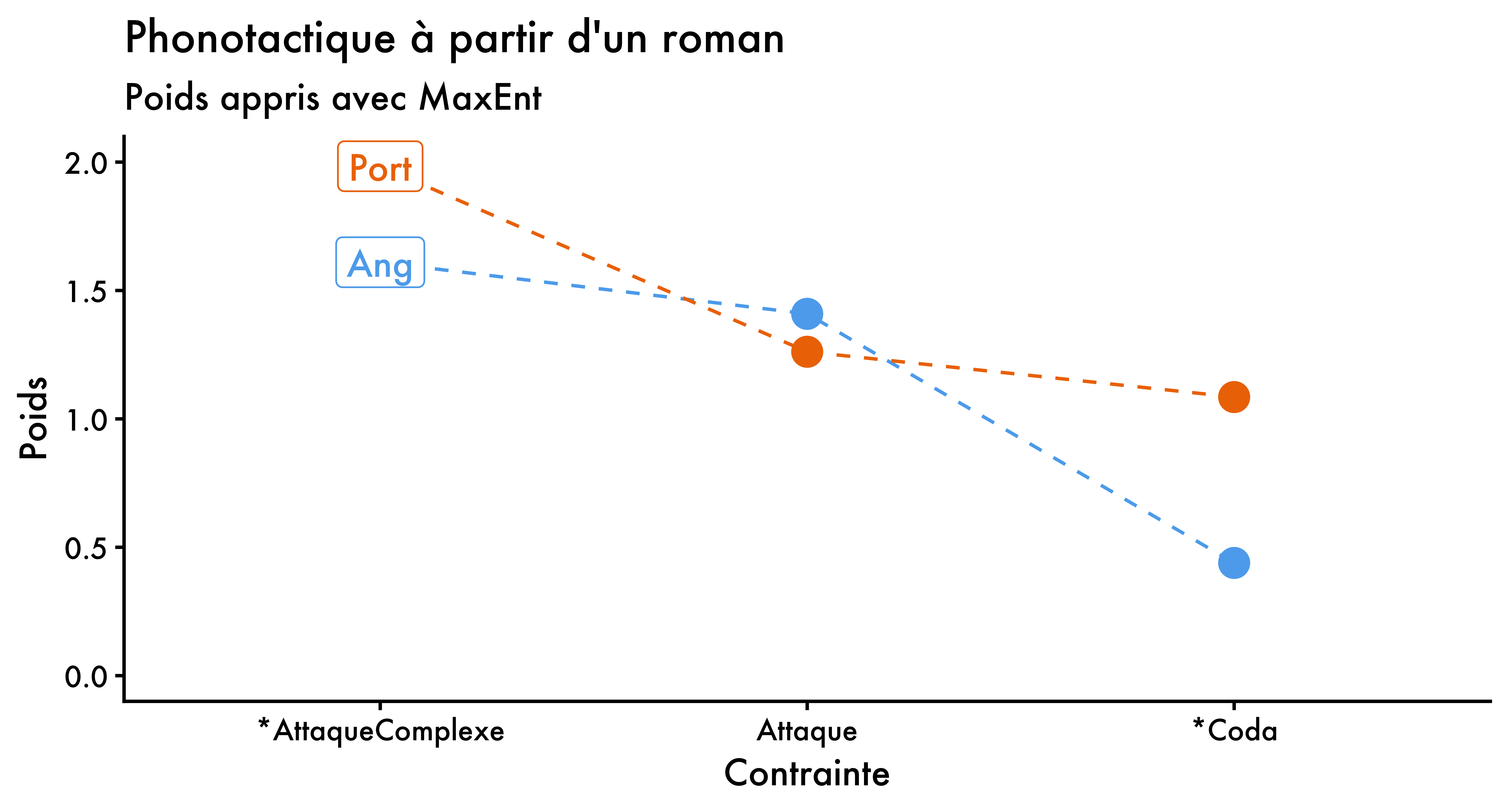
[1] -56665.07Sans surprise, no_coda et no_complex_onset ont tous deux des poids plus élevés en portugais qu’en anglais. Enfin, même s’il n’est pas très courant de visualiser les poids MaxEnt, nous pouvons facilement le faire pour mieux apprécier la façon dont les deux langues diffèrent sur le plan de leur phonotactique (du moins d’après les données analysées ici).
1weights_en <- tableau_md |>
maxent() |>
_$weights
weights_pt <- tableau_bc |>
maxent() |>
_$weights
2weights <- tibble(
lang = rep(c("Ang", "Port"), each = length(weights_pt)),
constraint = rep(names(weights_pt), times = 2),
weight = c(weights_en, weights_pt)
)
ggplot(data = weights,
aes(x = reorder(constraint, -weight),
y = weight,
color = lang)) +
geom_line(aes(group = lang, color = lang), linetype = "dashed") +
geom_point(size = 4) +
3 geom_label(data = weights |>
filter(constraint == "no_complex_onset"),
aes(label = lang)) +
theme_classic(base_family = "Futura") +
theme(legend.position = "none") +
labs(
x = "Contrainte", y = "Poids", color = "Langue :",
title = "Phonotactique à partir d'un roman",
subtitle = "Poids appris avec MaxEnt"
) +
scale_colour_manual(
values = c("steelblue2", "darkorange2")
) +
scale_x_discrete(
labels = c(
no_coda = "*Coda",
onset = "Attaque",
no_complex_onset = "*AttaqueComplexe"
)
) +
coord_cartesian(ylim = c(0, 2))- 1
- Extraire les poids des tableaux
- 2
- Créer un tibble avec les données à tracer2
- 3
- Identifier la langue avec des étiquettes
Copyright © Guilherme Duarte Garcia
Les références
Goldwater, Sharon, et Mark Johnson. 2003. « Learning OT constraint rankings using a Maximum Entropy model ». Proceedings of the Stockholm Workshop on Variation within Optimality Theory, 111‑20.
Hayes, Bruce, et Colin Wilson. 2008. « A maximum entropy model of phonotactics and phonotactic learning ». Linguistic Inquiry 39 (3): 379‑440. https://doi.org/10.1162/ling.2008.39.3.379.
Notes de bas de page
Vous remarquerez parfois des décalages, surtout si vous transcrivez des textes plus anciens, qui tendent à suivre d’anciens patrons orthographiques. Vous pouvez en voir un exemple ci-dessous : typographia en portugais, qui s’écrit maintenant tipografia. Tout cela signifie que la précision ne sera pas de 100 %, mais elle dépassera 80-85 % d’après des échantillons que j’ai testés récemment. Pour l’anglais, la précision sera beaucoup plus élevée, puisqu’il utilise des recherches lexicales (certainement au-dessus de 90 %).↩︎
Même s’il n’est généralement pas recommandé de relier des catégories sur l’axe des x avec des lignes, une ligne pointillée rend la figure plus facile à lire ici.↩︎